아까 전에 테스트를 이해하기 위해서 모 집단과 그와 관련된 정규 분포, zscore 이런 것들을 알아봤습니다.
test는 두 집단이 통계적으로 같은지 확인하기 위해 한다고 했습니다.
나름대로 이해해 보면 – 두 집단(표본)이 같다고 가정했을 때(귀무가설)-각 평균과 표준편차를 구할 수 있고, 비슷한 조건에서 시험을 계속하여 데이터를 얻어 나가면 모집단에 근접할 것이기 때문에, 결국 정규 분포(에 근사한) 곡선을 얻을 수 있는 – 두 정규 분포 곡선을 거듭했을 때, 표본 간 평균의 차이가 적으면 대부분 겹칠 것이기 때문에, 결국 정규 분포(에 근사한)하고 두 축 위쪽 비슷한) 볼 수 있다.-다만 정규 분포곡선에서 수치화하기에는 함수가 복잡할 정도로 이해했습니다. -그러나 통계에 문외한이기 때문에 좀 더 알기 쉽게 이해할 수 있는 방법이 있을 것 같습니다.
test는 정규성 검정-등분산 검정-test 단계로 진행됩니다.전술한 표본은 정규성을 만족해야 한다는 조건이 붙어 있어 테스트에서 두 표본의 분산은 같다고 가정하기 위해 test 전체 정규성 검정과 등분산 검정을 실시합니다.정규성 검정
정규성은 주로 표본의 개수와 관련이 있는 듯하나 t분포곡선을 보면
출처 : http://www.statisticsh owto.com/probability-and-statistics/t-test/
표본수가 적을수록(df_자유도 n-1_로 표현) 상대적으로 무게중심이 낮게 퍼지는 형태가 되며, 같은 5% 수준이라도 tscore가 더 커질 것입니다.
그러면 tscore가 큰, 즉 두 표본 평균의 차이가 비교적 커도 두 집단이 같다는 귀무 가설을 만족할 수 있게 되고, 아무래도 에러가 발생할 확률이 높아지므로 (불확실성이 증가) 표본 수는 클수록 좋습니다.
표본수에 관해서는, 정규성을 만족하는 표본에 대한 검정을 모수 검정, 정규성을 채우지 않는 표본에 대한 검정은 비모수적 검정이라고 하고, 이 구분은 표본 개수가 큰 영향을 미치는 것 같습니다. 중앙값, 최빈값, 첨도, 왜도, 최대 최소값 등 잘 모르는 용어가 많지만 적어도 시험에서는 정확도가 중요하기 때문에 표본은 크게 나는 값이 없고 완만하다고 가정해야 합니다.
표본 개수에 따른 정규성 유무와 검정방법은 표본이 30개 이상이면 중심 극한정리에 따라 정규분포로 가정하거나 Shapiro-wilk test(30개 미만) 또는 Kolmogorov-smirnov(30개 이상) test가 있습니다.귀무 가설(정규 분포를 따른다)과 대립 가설(정규 분포를 따르지 않는다)을 pvalue 0.05로 검증합니다.
보통 30개 이상이면 처음부터 정규 분포라고 가정을 하는 경우가 많다고 하며, 30개 미만일 때 검증 방법인 Shapiro-wilk test는 계산 가능한 사이트가 있습니다.https://www.statskingdom.com/shapiro-wilk-test-calculator.htmlShapiro-WilkTestCalculator*Themaximumsamplesizeis5000Name:Significancelevel(α):Outliers:Rounding:Data:7,1,2,168,2,11CalculateClearLoadlastrunWhenenteringdata, press comma , , Space or Enter after each value. You may copy and paste data from Excel or Google Sheets . www.statskingdom.com표본이 10개 미만의 경우 정규성을 채우지 못하고 비 털 수통계 검정 방법을 사용하지만, 독립 표본은 Wilcoxon’s rank-sum test(윌콕슨 순위 합 검정, Mannwhitney U) 대응 표본은 Wilcoxon’s signed rank test(윌콕슨 부호 순위 검정)를 사용하여(귀무 가설) 중심값의 차이가 없다. ↔(대립 가설) 중심값의 차이가 있다 pvalue여기서평균대신중심치를사용하는이유는정규성을만족하지않으면평균이무의미하기때문이라고생각합니다.
가이드라인의 예로 돌아오면,
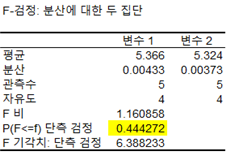
표본은 각 5개씩입니다.
앞에서 본 바로는 표본 수가 적기 때문에 비모수 통계방법 중 Wilcoxon’s rank-sum test (Mannwhitney U)를 적용해야 되는데 가이드라인에서는 test 검정을 활용했습니다. 비모수 방법이 검정력이 떨어지는 이유도 있고 시험에서는 정확도(모여 있는 정도)가 중요하기 때문에 적절히 시험을 실시하면 반복적으로 같은 값이 계속될 것이므로 표본이 적어도 정규성을 만족한다고 가정하고 테스트로 검정한 것이 아닐까 생각합니다.등분산 검정
등분산검정과 test는 엑셀로 계산이 가능(파일탭-(하단) 옵션-추가기능-분석도구)입니다. 등분산검정에 따라 등분산 여부에 따라 test의 계산이 달라집니다.
- 엑셀 메뉴-데이터-데이터 분석의 기술통계법(출력옵션의 요약통계량을 클릭)
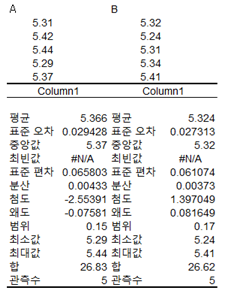
한쪽검정 0.4443 이므로 p 0.05 (여기서는 한쪽이므로 0.025)보다 크기 때문에 분산에 차이가 없다고 가정, F-검정에서는 계산상 양쪽이 아닌 한쪽검정이라고 판단한다는 test
엑셀 메뉴 – 데이터 분석의 t – 검정 : 등분산가정 두 집단 ※ 분산이 같지 않으면 분산가정 두 집단
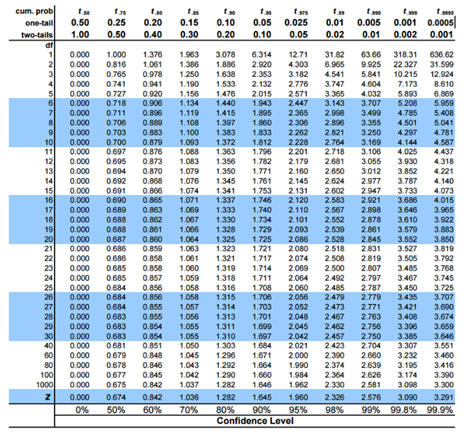
t값은 1.046으로 양쪽 검정 0.3261은 p0.05보다 크기 때문에 귀무가설에 만족해 두 집단(시험자)의 평균치에는 차이가 없다.
table에서는
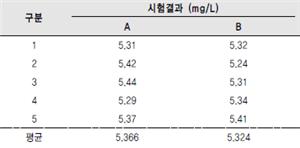
http://www.ttable.org/표준 정규 분포 표와 시각이 조금 다르지만, 표준 정규 분포 표는 z값의 확률을 나타냅니다만, table은 확률에 의해t값을 나타냅니다. 표 상단 two-tails(양측 검정)0.05기준(7번 열)에서 자유도에 따라서 나온다 t치와 실제 요구한 t값을 비교하면 좋지만 자유도 8(5+5– 2)의 2.306보다 아까 요구한 t치 1.046은 작아서 돌아간 가설을 만족하게 됩니다. Wilcoxon’s rank-sum test(Mann whitney U)
전술한 표본 수가 적다고 정규성을 충족시키지 않다고 생각하므로 test와는 별도인 털 수 검정 방법인 Wilcoxon’srank-sumtest(MannwhitneyU)을 적용하고 보겠습니다.
참고:GrahamHoleResearchSkillsMann-Whitneytesthandoutversion1.0.
두개의 독립 표본에서 정규성이 없는지 분산이 큰 비 털 수적 경우에 사용하는 방법이라고 소개되고 있습니다. 모든 데이터에 순위를 매기, 조별 순위의 합을 비교하는데 U값으로 표현합니다.다른 검정과 달리 U값은 작을수록 우연히 일어날 가능성이 적다고 생각합니다. 그러므로 돌아간 가설이 기각되면서 2개 표본은 차이가 있다는 것입니다.
예를 들어 U값을 요구하자 1. 그룹 관계 없이 값이 낮은 순부터 순위 부여, 동일한 값이 있으면 평균치를 주자(예를 들면 1,2위가 같은 데이터가 있으면 1.5부여).
2. 각 순위를 그룹별로 매끈하게 더하기 A= 3.5+9+10+2+7= 31.5B= 5+1+3.5+6+8= 23.5
3. 두 순위의 합계가 큰 것(높은 순위의 합계)을 TX라 한다. 표본 A 순위의 합계인 31.5가 TX
4.U값계산U=N1*N2+NX*(NX+1)/2-TX=5*5+5*(5+1)/2-31.5=25+15-31.5=8.5
N1 (A 표본 개수), N2 (B 표본 개수), NX (TX 값이 있는 표본의 개수)
5. Utable 검증
Pvalue 0.05에 있어서의 값 N1과 N2가 각각 5이므로, U치는 2가 되는 A, B표본으로 구할 수 있던 U치는 8.5이므로, 5%수준의 U치인 2보다 크고, 귀무가설을 만족하고 있으므로 A와 B 의 평균치의 차이는 없다고 하는 결론입니다.이상으로 두 표본에 대한 통계적 비교 방법에 대해 알아보았습니다. 2개 이상의 동시 비교도 필요하며, 그 방법은 ANOVA(분산분석)에서 소개되고 있습니다만, 기회가 있으면 정리해 보도록 하겠습니다.
참고자료 블로그 – https://blog.naver.com/pmw9440/221945754297- https://blog.naver.com/cutegirl8856/221981290170 발간물 – Graham Hole Research Skills Mann – Whitney testhandout version 1.0.