자율주행 자동차는 미래입니다. 앞으로 20년 안에 우리는 차 안에 들어가서 이런 일을 할 수 있을 겁니다.
좋아요, 포켓몬 고는 하지 않을지도 모르지만, 우리는 기본적으로 우리가 원하는 것은 무엇이든 차 안에서 할 수 있을 겁니다. 낮잠을 잘 수도 있고, 뉴스를 읽을 수도 있고, 친구들과 화상채팅을 할 수도 있죠. 그 차는 우리를 위해 모든 운전을 해주고, 우리가 길에서 시간을 절약할 수 있게 해줄 거예요.
자율주행 자동차는 생명도 살릴 수 있습니다. 매년 33,000명 이상의 미국인이 자동차 사고로 사망하고 있습니다. 자율주행의 차이가 실현되면 정확하고 안전한 이동이 가능하고, 이러한 불필요한 사고를 줄일 수 있을 것입니다.
그렇다면 왜 자율주행차는 이 놀라운 기술 분야에서 그렇게 발전했을까? 그리고 그들은 얼마나 더 멀리 가야 할까요? 그게 다음 몇 문장에서 다룰 내용입니다.
인지(#Perception)
자율주행자동차에는 Camera, Radar, LiDAR와 같은 시각입력장치가 필요하여 자동차가 주변세계를 인식하고 디지털 지도를 만들 수 있습니다. 우리는 차가 물체를 감지하는 영상을 집중적으로 찍습니다. 예를 들면
도대체 차는 어떻게 이런 걸 하는 거죠? 컴퓨터 비전(Computer Vision)을 이용하는 기계 학습(Machine Learning)과 AI!
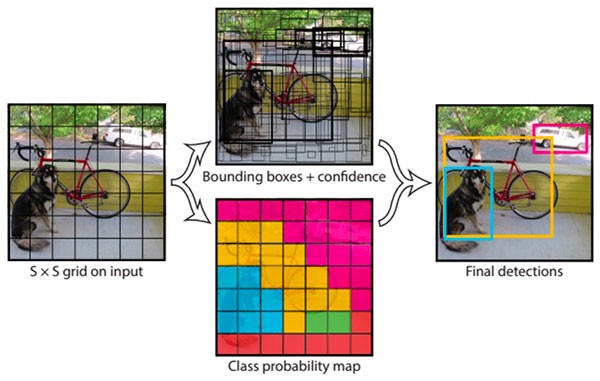
이미지 분류(Image Classification) 객체 검지는 사실 두 부분으로 이루어진 프로세스로 이미지 분류(Image Classification)와 이미지 위치 설정(Image Localization)이다. 이미지 분류는 자동차 또는 사람과 같이 이미지의 오브젝트가 무엇인지를 판단하는 것이며 이미지 위치는 위의 경계상자에 표시된 것처럼 이들 오브젝트의 특정 위치를 제공합니다.
이미지 분류를 위해 교통신호기나 보행자와 같은 다양한 물체를 인식하도록 컨볼루션 뇌신경망(Convolutional Neural Network, CNN)을 훈련시킵니다. CNN은 이들을 분류하기 위해 이미지에 대한 컨볼루션(convolution) 작업을 합니다.

콘볼루션 신경망 (Convolutional Neural Network)
그러나 그러한 CNN은 대개 그 상당 부분을 차지하는 하나의 물체만으로 이미지를 분류하는데, 이 문제를 해결하기 위해 우리는 슬라이딩 윈도(Sliding Windows)를 사용할 수 있습니다!

슬라이딩창 알고리즘 (Sliding window salgorithm)
Windows를 이미지 위로 미끄러뜨렸을 때, 결과적인 이미지 패치를 가져와 그것이 가능한 어떤 물체와 일치하는지 보기 위해 CNN을 통해 그것을 작동시킵니다. 만약 그것이 단지 길이나 하늘의 이미지라면 잘못된 추측일 것입니다 “만약 그것이 자동차와 사람의 이미지라면, 진정한 추측으로 돌아올 것입니다”
슬라이딩 윈도우어 프로젝트 영상 결과
그런데 windows보다 훨씬 크거나 작은 물체가 있으면 어떻게 될까요? 감지되지 않을 것입니다! 그래서 우리는 여러 개의 창문 크기를 사용하여 그것들을 이미지 위에 미끄러뜨려야 합니다. 이것은 계산하는 데 매우 비싸고 시간이 걸릴 수도 있기 때문에 우리는 또 다른 알고리즘인 YOLO(You Only Look Once)를 소개합니다.
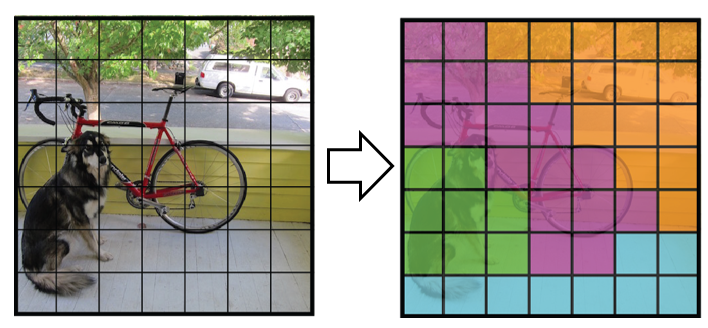
그리고 그것은 단지 한 번만 살아있는 것이 아니라 그 이미지가 CNN을 통해 한 번만 보이는 것이기 때문에 그것은 오직 한 번만 보이는 것(You Only Look Once)입니다. YOLO를 위해 우리는 이미지를 격자망으로 나누고 전체 이미지를 신경회로로 작동시킵니다.
이미지를 그리드로 분할하여 출력으로 클래스 확률 맵을 획득
우리는 클래스 확률을 얻게 되는데, 이는 우리에게 각 그리드 셀이 특정 개체일 확률을 높입니다. YOLO는 전체화상의 작은 부분에 대한 추측을 반납하고 여러 개의 창문크기나 리허설과정(run-throughs)이 필요하지 않기 때문에 효과가 있습니다.
이미지 위치설정(Image Localization)에서는 각 그리드 셀이 무엇을 포함하는지 알았으므로(또는 어느 것도 포함하지 않는 경우) 각 오브젝트가 경계상자(bounding box)를 사용하는 위치를 어떻게 정확하게 정합니까?
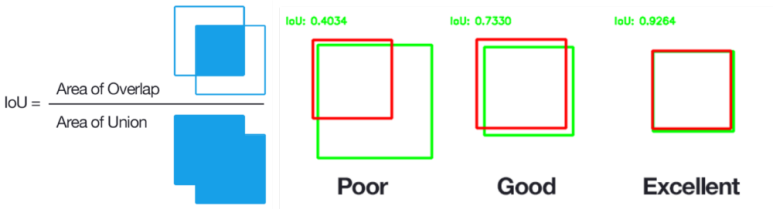
우리는 비최대억제(non-max suppression)라 불리는 알고리즘을 사용합니다. 네트워크를 훈련하는 동안, 우리는 CNN에서 나온 우리 경계함의 결과를 실제 경계함과 비교합니다. 우리의 비용 함수는 교차 영역을 두 개의 경계 상자의 합 집합 영역으로 나눈 것입니다. IoU(intersection overunion)라고도 불리는 이 숫자가 1에 가까울수록 우리의 추측은 더 좋은 것입니다.
IoU계산
우리의 네트워크를 훈련 세트에 걸친 경계 상자를 예측하도록 훈련하고 시험을 시작함으로써 우리는 또한 동일 물체의 일부가 다중 그리드 셀에 있을 수 있고 다중 경계 상자가 발생할 수도 있음을 고려해야 합니다. 이것은 비최대 억제(non-max suppression)를 요구합니다.
non-max suppression의 경우 우리는 먼저 어떤 물체가 일반적으로 0.5 또는 0.6의 특정 임계값 이하로 존재할 수 있는 그리드 셀에서 경계 상자를 폐기합니다. 그런 다음 예측치가 가장 높은 상자를 가져와서 IoU가 다른 임계값보다 큰 상자를 폐기하거나 억제하는데, 이는 또한 편리하게 0.5 또는 0.6입니다.
이것이 왜 non-max suppression 알고리즘이라고 불리는지 간단하게 알 수 있습니다. 우리는 최대 확률이 없는 상자를 가지고 그것들을 억제할 것입니다!
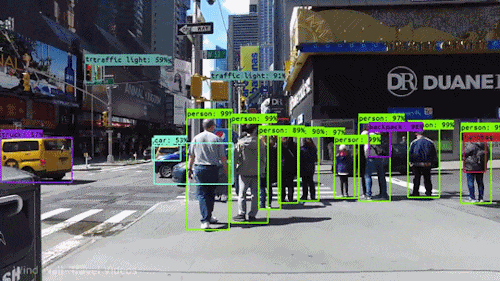
오브젝트 탐지 및 위치를 수행한 후 결과를 얻습니다!

자동차는 YOLO나 다른 알고리즘을 사용하여 주변의 물체를 감지하고 봄으로써 결정을 내릴 수 있습니다. 그들이 결정할 수 있도록 인간, 다른 차, 신호등, 다른 모든 것을 볼 수 있을 것이다. 오브젝트 감지를 이용하여 자동차는 인간이 할 수 있는 것처럼 세상을 볼 수 있을 것입니다.
하지만 대체 어떻게 자율 주행차를 세울 수 있는 것일까요.
객체 감지의 다음 단계는 먼저 자동차는 빠르게 접근하는 물체를 감지하고, 이를 피하기 위해 실시간으로 물체를 감지해야 합니다. 높은 정밀도를 위해서는 매우 짧은 지연시간이 필요한데 이는 매우 높은 컴퓨팅과 그래픽 능력이 필요하다는 것을 의미합니다. 자율주행 자동차에 대한 컴퓨터 비전(Computer Vision)을 안전하게 실현하기 위해 프로세서 유닛의 전력을 개선해야 합니다.

그러나 우리는 99.9% 이상의 매우 정확한 모델이 필요합니다. 왜냐하면어떤실수도재해가돼서인명손실이발생할수있다라는거죠. 우리의 현재 모델은 아직 그다지 높은 가치를 달성하지 못하고 있으며, 우리는 더 좋은 모델을 훈련하고 디자인하기 위해 더 많은 데이터를 생산해야 합니다. R-FCN 및 SSD와 같은 객체 감지를 위한 다른 모델이 있지만 우리가 필요로 하는 정확성은 아직 멀었습니다. 오브젝트 검지를 크게 개선할 수 있다면 자율주행차에 한 걸음 더 가까이 다가갈 수 있어 더욱 안전하고 편리한 미래가 될 것입니다.
요점(Key Take aways)
●자동차는 주변 환경을 감지하기 위해 물체 감지가 필요하다.
● 객체 감지 = 객체 분류 + 객체 위치 설정
●YOLO 알고리즘은 CNN을 통해 전체 이미지를 한 번만 실행하면 되지만 슬라이딩 윈도 알고리즘은 훨씬 계산 비용이 많이 든다.
●사용할 경계상자를 파악하기 위해 비최대억제(Non-max suppression)가 사용된다.
●우리는 아직 완벽한 물체를 감지하려면 멀었지만, 그곳에 가기 위해 열심히 노력할 것이다!
끼어들기 정말 오랜만에 소프트웨어에 대해 알려드리는군요. 하아~~게으르륵~~
이번 뉴스는 자율주행차가 외부 물체(객체)를 어떻게 인식하는지에 대해 간단히 설명하는 글이었습니다. 처음 접하시는 분들은 어! 이런 어려운 문장을… 라고 생각할 수도 있고 이런 기초 문장을… 라고 생각하시는 분들도 계실 거예요. 블로그를 시작하면 전해드리고자 하는 뉴스는 되도록 쉽게 설명하는 것을 목표로 하기 때문에 가능하면 기술적이지 않고 전문적이지 않고 내용 전달이 어렵지 않은 글을 쓰려고 합니다. 하지만 가끔은 그렇지 않을 수도 있는데요. 그래도 꾸준히 제 블로그에 시간 투자를 하면 나름대로 자율주행차에 대한 기본적인 내용과 최신 정보는 들을 수 있다고 생각합니다.
자율주행차가 발전하게 된 가장 결정적인 원인 중 하나는 바로 이 컴포넌트 기술이라고 생각합니다. 이전까지는 단순한 전기센서나 이미 매설되어 있는 전기선이 있는 정해진 구간에서만 운행되는 자율주행차(?)라면 computervision과 AI 기술의 발전은 사람과 똑같은 시각 능력을 가진 자동차를 만들어 낼 수 있게 되었다고 할 수 있습니다. 이러한 시각 인지 능력은 하나만 이용하는 것이 아니라 Camera, Radar, LiDAR 세 가지를 종합적으로 분석한 결과를 자동차 운행에 이용하고 있는 것입니다. 관련 문장은 아래에 첨부합니다. 각 센서에 대해 알고 싶다면 아래를 참고하세요.
이번 글은 하드웨어적으로 이렇게 수집된 Data를 어떻게 처리하고 자율주행차가 운행하는 객체를 구분하는지에 대해서 소개하는 글입니다. 이러한 이미지 처리 기술은 우리가 현재 휴대폰에서 사용하고 있는 이미지 인식 기술인 AI의 과정과 같은 것입니다. 하긴 휴대전화의 그런 기술을 얼마나 사용하고 아시는지는 모르겠지만 제 주변에는 그런 기능 자체도 모르는 분들이 많아요. 현재 우리 생활에서 많이 접할 수 있는 AI 기술은 크게 음성인식, 이미지 인식 정도가 아닐까 싶습니다. 그 외에도 AI 기술은 조금씩 우리의 생활 속으로 들어오고 있습니다. 어쨌든 최근 가장 핫한 AI 기술은 이미지 기술인 것은 확실해요. 이러한 기술의 발전은 자율주행자동차의 발전과도 큰 관계가 있기 때문에 지속적인 발전이 필요한 분야임에는 분명합니다.
이번글을통해쉽게이미지인식기술에대해이해할수있는기회가되었으면합니다.
◆ 자동운전 자동차 시각센서에 대한 글입니다.이전의 ‘자율주행차란?’ “주제로 자율주행차에 대한 정의를 다시 확인해봅시다. 자율주 blog.naver.com
크리스마스 이브네요 모두 산타클로스에게 큰 선물을 받으세요. ^^
PS: 검색에 들어가서 원하는 내용을 찾을 수 없다면 태그 또는 검색을 하면 더 많은 자료를 찾을 수 있습니다. 자율주행자동차 기반의 미래 모빌리티에 대한 보다 자세한 문의나 강의는 [email protected]으로 연락 바랍니다.
Over the Vehicle !!!
참고자료 UsingComputerVisionforObjectDetectiontowardsdatascience.com